
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 데이터분석가
- ai 새싹 부트캠프 7일차
- 새싹 AI데이터새싹 엔지니어 부트캠프
- 새싹 AI데이터새싹 엔지니어 부트캠프 2일차
- ai 새싹 부트캠프 6일차
- 데이터관련면접
- 새싹 AI데이터새싹 엔지니어 부트캠프 3일차
- ai 새싹 부트캠프 5일차
- 새싹 AI데이터새싹 엔지니어 부트캠프 1일차
- T
- ㅂ.
- ai 새싹 부트캠프 4일차
- 통계용어 정리
- Til
- X
- 데이터분석가면접준비
- 취준생
- ASAC
- Today
- Total
데이터 공부기록
[DATA_SET]MAKE_MOONS 본문
INDEX
0. [DATA_SET]Moons
01. CODE :
0. [DATA_SET]MOONS
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_moons.html
sklearn.datasets.make_moons
Examples using sklearn.datasets.make_moons: Classifier comparison Comparing different clustering algorithms on toy datasets Comparing different hierarchical linkage methods on toy datasets Comparin...
scikit-learn.org
sklearn.datasets.make_moons(n_samples=100, *, shuffle=True, noise=None, random_state=None)
`make_moons`함수는 Scikit-learn 라이브러리에서 제공하는 함수 중 하나로, 가상의 *Cluster (클러스터) 를 두 개의 서로 교차하는 반달 모양을 만듭니다.
군집화 및 분류 알고리즘을 시각화하기 위한 간단한 가상 데이터셋입니다.
parameters 설명
| 매개변수 | 설명 | 기본값 |
| n_samples | int 또는 shape이 (2,)인 튜플, dtype=int, 기본값은 100입니다. | 생성된 전체 포인트 수입니다. 또는 두 개의 반달 각각의 포인트 수입니다. |
| shuffle | bool, 기본값은 True입니다. | 샘플을 섞을지 여부입니다. |
| noise | float, 기본값은 None입니다. | 데이터에 추가되는 가우시안 노이즈의 표준 편차입니다. |
| random_state | int, RandomState 인스턴스 또는 None, 기본값은 None입니다. | 데이터셋 섞기 및 노이즈 생성을 위한 난수 생성을 결정합니다. |
Return
- X: (n_samples, 2) 모양의 ndarray. 생성된 샘플입니다.
- y: (n_samples,) 모양의 ndarray. 각 샘플의 클래스 소속을 나타내는 정수 레이블(0 또는 1)입니다.
이 함수는 주로 클러스터링 알고리즘을 시험하거나 시각화하기 위한 가상 데이터셋을 만드는 데 사용됩니다. 또한, 지도 학습 알고리즘의 성능을 평가하고자 할 때도 사용될 수 있습니다. 이 함수를 이용하여 간단한 형태의 가상 데이터를 생성하고, 이를 통해 머신러닝 모델을 실험하고 테스트하는 데 유용하게 활용할 수 있습니다.
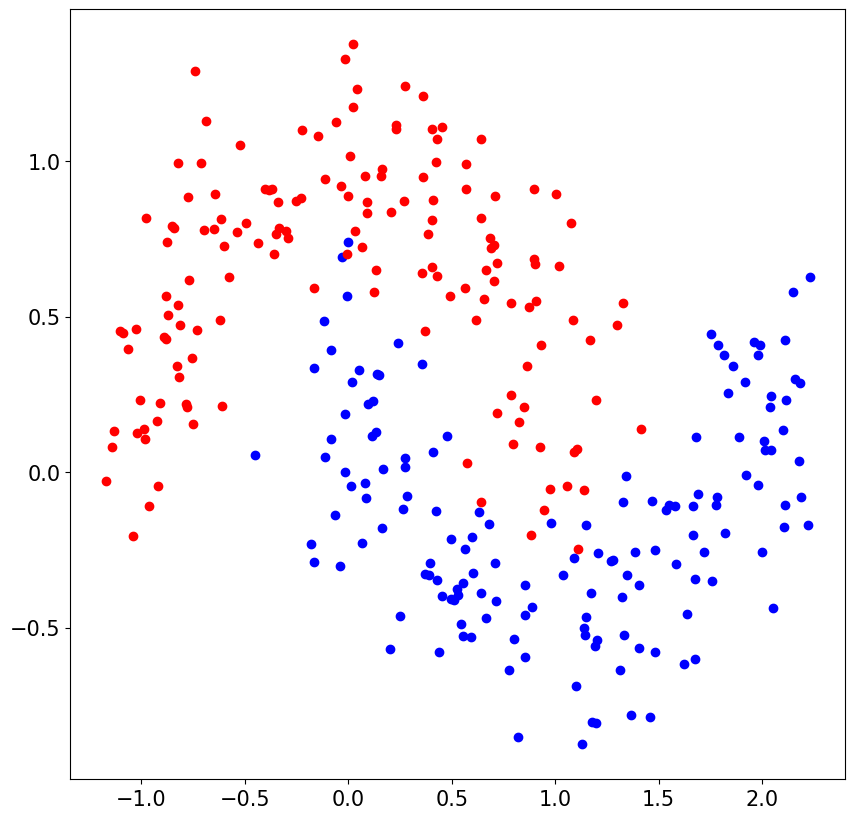
01. CODE :
# pos는 양성(positive) 클래스를 의미하고, neg는 음성(negative) 클래스를 나타냅니다
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
n_samples = 300
X ,y = make_moons(n_samples=n_samples, noise=0.2)
fig, ax = plt.subplots(figsize=(10,10))
X_pos, X_neg = X[y == 1], X[y == 0]
ax.scatter(X_pos[: , 0], X_pos[:,1],color='blue')
ax.scatter(X_neg[:,0], X_neg[:, 1],color='red')
ax.tick_params(labelsize=15)
plt.show()
* make_moons로 만들어지는 dataset은 직선으로 나눌 수 없음 → 여러 레이어들을 이용하여 모델을 만들어야 함
'sesac ai 과정 > DL' 카테고리의 다른 글
| [Convoluitonal_Neural_Networks] Sobel Filtering (2) | 2023.11.24 |
|---|---|
| [PyTorch] "HELLO PyTorch!" (0) | 2023.11.19 |
| [DATA_SET]BLOBS (0) | 2023.11.19 |


